- CHAPTER 1 Reliable, Scalable, and Maintainable Applications
- CHAPTER 2 Data Models and Query Languages
- CHAPTER 3 Storage and Retrieval
CHAPTER 1 Reliable, Scalable, and Maintainable Applications
Thinking About Data Systems
One possible architecture for a data system that combines several components.
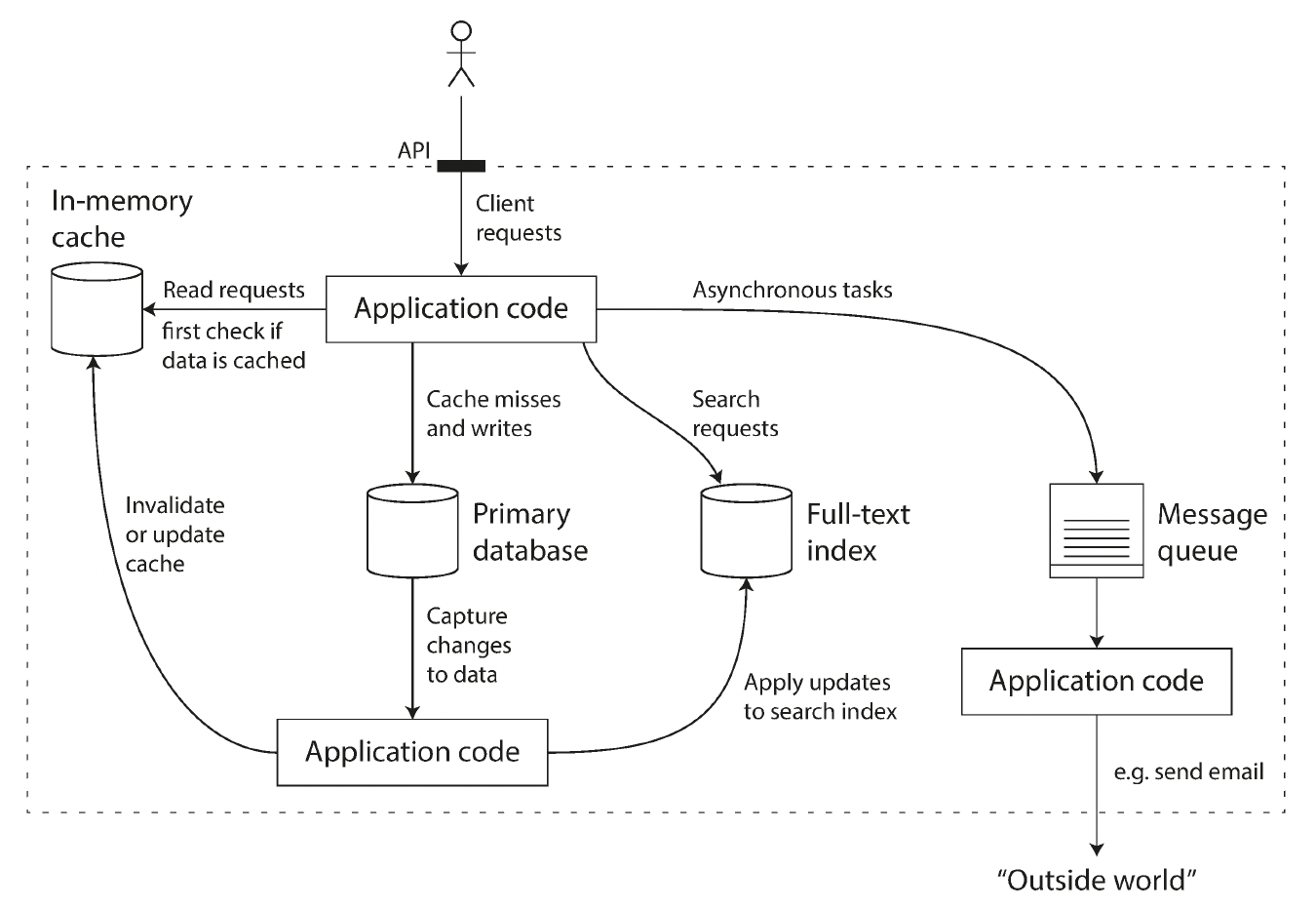
Three concerns that are important in most software systems:
Reliability
- The system should continue to work correctly (performing the correct function at the desired level of performance) even in the face of adversity (hardware or software faults, and even human error).
Scalability
- As the system grows (in data volume, traffic volume, or complexity), there should be reasonable ways of dealing with that growth.
Maintainbility
- Over time, many different people will work on the system (engineering and operations, both maintaining current behavior and adapting the system to new use cases), and they should all be able to work on it productively.
Reliability
Human Errors
One study of large internet services found that configuration errors by operators were the leading cause of outages, whereas hardware faults (servers or network) played a role in only 10–25% of outages.
How do we make our systems reliable, in spite of unreliable humans?
- Design systems in a way that minimizes opportunities for error. For example, well-designed abstractions, APIs, and admin interfaces.
- Decouple the places where people make the most mistakes from the places where they can cause failures. In particular, provide fully featured non-production sandbox environments where people can explore and experiment safely, using real data, without affecting real users.
- Test thoroughly at all levels, from unit tests to whole-system integration tests and manual tests. Automated testing is widely used.
- Allow quick and easy recovery from human errors, to minimize the impact in the case of a failure. For example, make it fast to roll back configuration changes, roll out new code gradually (so that any unexpected bugs affect only a small subset of users), and provide tools to recompute data.
- Set up detailed and clear monitoring, such as performance metrics and error rates.
- Implement good management practices and training—a complex and important aspect.
Scalability
Describing Load
Let’s consider Twitter as an example.
Twitter’s scaling challenge is not primarily due to tweet volume, but due to fan-out - each user follows many people, and each user is followed by many people. There are broadly two ways of implementing these two operations:
-
Posting a tweet simply inserts the new tweet into a global collection of tweets. When a user requests their home timeline, look up all the people they follow, find all the tweets for each of those users, and merge them (sorted by time).

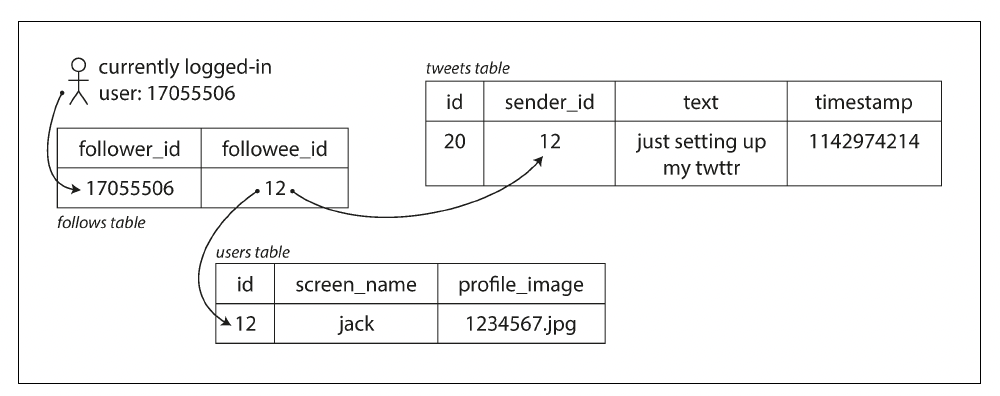
-
Maintain a cache for each user’s home timeline—like a mailbox of tweets for each recipient user. When a user posts a tweet, look up all the people who follow that user, and insert the new tweet into each of their home timeline caches. The request to read the home timeline is then cheap, because its result has been computed ahead of time.
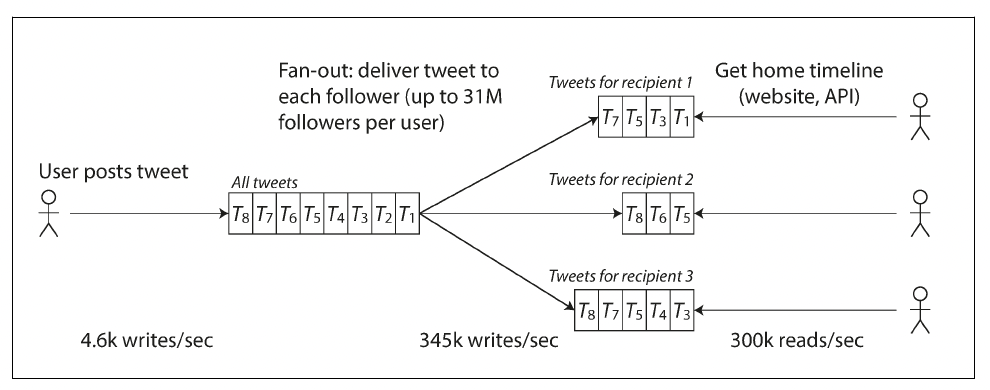
The first version of Twitter used approach 1, but the systems struggled to keep up with the load of home timeline queries, so the company switched to approach 2. This works better because the average rate of published tweets is almost two orders of magnitude lower than the rate of home timeline reads, and so in this case it’s preferable to do more work at write time and less at read time.
In the example of Twitter, the distribution of followers per user (maybe weighted by how often those users tweet) is a key load parameter for discussing scalability, since it determines the fan-out load.
The final twist of the Twitter anecdote: now that approach 2 is robustly implemented, Twitter is moving to a hybrid of both approaches. Most users’ tweets continue to be fanned out to home timelines at the time when they are posted, but a small number of users with a very large number of followers (i.e., celebrities) are excepted from this fan-out. Tweets from any celebrities that a user may follow are fetched separately and merged with that user’s home timeline when it is read, like in approach 1.
Approaches for Coping with Load
People often talk of a dichotomy between scaling up (vertical scaling, moving to a more powerful machine) and scaling out (horizontal scaling, distributing the load across multiple smaller machines).
Maintainability
We will pay attention to three design principles for software systems:
-
Operability
- Make it easy for operations teams to keep the system running smoothly.
-
Simplicity
- Make it easy for new engineers to understand the system, by removing as much complexity as possible from the system.
-
Evolvability
- Make it easy for engineers to make changes to the system in the future.
CHAPTER 2 Data Models and Query Languages
Relational Model Versus Document Model
Document Model: The main arguments in favor of the document data model are schema flexibility, better performance due to locality, and that for some applications it is closer to the data structures used by the application.
Relational model: The relational model counters by providing better support for joins, and many-to-one and many-to-many relationships.
Query Languages for Data
Declarative languages, like SQL, have a better chance of getting faster in parallel execution because they specify only the pattern of the results, not the algorithm that is used to determine the resules.
Imperaive code is very hard to parallelize across multiple cores and multiple machines, because it specifies instructions that must be performed in a particular code.
Declarative Queries on Web
In a web browser, using declarative CSS styling is much better than manipulating styles imperatively in JavaScript. Similarly, in databases, declarative query languages like SQL turned out to be much better than imperative query APIs.
MapReduce Querying
MapReduce is a programming model for processing large amounts of data in bulk across many machines, popularized by Google. A limited form of MapReduce is supported by some NoSQL datastores, including MongoDB and CouchDB, as a mechanism for performing read-only queries across many documents.
MapReduce is neither a declarative query language nor a fully imperative query API, but somewhere in between: the logic of the query is expressed with snippets of code, which are called repeatedly by the processing framework. It is based on the map (also known as collect) and reduce (also known as fold or inject) functions that exist in many functional programming languages.

The map function would be called once for each document, resulting in emit(“1995-12”, 3) and emit (“1995-12”, 4). Subsequently, the reduce function would be called with reduce(“1995-12”, [3, 4]), returning 7.
MapReduce is a fairly low-level programming model for distributed execution on a cluster of machines. Higher-level query languages like SQL can be implemented as a pipeline of MapReduce operations.
A declarative query language offers more opportunities for a query optimizer to improve the performance of a query.
CHAPTER 3 Storage and Retrieval
Data Structures That Power Your Database
Hash Indexes
A storage engine like Bitcask is well suited to situations where the value for each key is updated frequently.
Lots of detail goes into making this simple idea work in practice. Briefly, some of the issues that are important in a real implementations are:
File format
- CSV is not the best format for a log. It’s faster and simpler to use a binary format that first encodes the length of a string in bytes, followed by the raw string (without need for escaping).
Deleting records
- If you want to delete a key and its associated, you have to append a special deletion record to the data file (sometimes called a tombstone). When log segments are merged, the tombstone tells the merging process to discard any previous values for the deleted key.
Crash recovery
- Bitcask speeds up recovery by storing a snapshot of each elements’s hash map on disk, which can be loaded into memory more quickly.
Partially written records
- The database may crash at any time, including halfway through appending a record to the log. Bitcask files include checksums, allowing such corrupted parts of the log to be detected and ignored.
Concurrenncy control
- As writes are appended to the log in a strictly sequential order, a common implementation choice is to have only one writer thread. Data file segments are append-only and otherwise immutable, so they can be read concurrently by multiple threads.
An append-only logs seems wasteful at first glance: why don’t you update the file in place, overwriting the old value with the new value? But an append-only design turns out to be good for several reasons:
-
Appending and segment merging are sequential write operations, which are generally much faster than random writes, expecially on magnetic spinning-disk hard drives.
-
Concurrenct and crash recovery are much simpler if segment files are append-only or immutable. For example, you don’t have to worry about the case where a crash happened while a value was being overwritten, leaving you with a file containing part of the old and part of the new value spliced together.
-
Merging old segments avoids the problem of data files getting fragmented over time.
However, the hash table index also has limitations:
-
The hash table must fit in memory. It is difficult to make an on-dish hash map perform well. It requires a lot of random access I/O, it is expensive to grow when it becomes full, and hash collisions require fiddly logic.
-
Range queries are not efficient. For example, you cannot easily scan over all keys between kitty00000 and kitty99999 - you have to look up each key individually in the hash maps.
SSTables and LSM-Trees
SSTable: Sorted String Table
Constructing and maintaining SSTables
We can now make our storage engine work as follows:
-
When a write comes in, add it to an in-memory balanced tree data structure (for example, a red-black tree). This in-memory tree is sometimes called a memtable.
-
When the memtable gets bigger than some threshold, write it out to disk as an SSTable file. This can be done efficiently because the tree already maintains the key-value pairs sorted by key. The new SSTable file becomes the most recent segment of the database. While the SSTable is being written out to disk, writes can continue to a new memtable instance.
-
In order to serve a read request, first try to find the key in the memtable, then in the most recent segment of the database, then in the next-older segment, etc.
-
From time to time, run a merging and compaction process in the background to combine segment files and to discard overwritten or deleted values.
This scheme works very well. It only suffers from one problem: if the databse crashed, the most recent writes (which are in the memtable but not yet written out to disk) are lost.
In order to avoid that problem, we can keep a separate log on disk to which every write is immediately appended. Every time the memtable is written out to an SSTable, the corresponding log can be discarded.
Making an LSM-tree out of SSTables
LSM-tree: Log-Structured Merge-Tree
Storage engines that are based on this principle of merging and compacting sorted files are often called LSM storage engines.
Lucene, an indexing engine for full-text search used by Elasticsearch and Solr, uses a similar method for storing its term dictionary. A full-text index is much more complex than a key-value index but is based on a similar idea: given a word in a search query, find all the documents (web pages, product descriptions, etc.) that mention the word. This is implemented with a key-value structure where the key is a word (a term) and the value is the list of IDs of all the documents that contain the word (the postings list). In Lucene, this mapping from term to postings list is kept in SSTable-like sorted files, which are merged in the background as needed.
Performance optimizations
The LSM-tree algorithm can be slow when looking up keys that do not exist in the database: you have to check the memtable, then the segments all the way back to the oldest (possibly having to read from disk for each one) before you can be sure that the key does not exist. In order ro optimize this kind of access, storage engines often use additional Bloom filters. (A Bloom filter is a memory-efficient data structure for approximating the contents of a set. It can tell you if a key does not appear in the database, and thus saves many unnecessary disk reads for nonexistent keys.)
B-Trees
Like SSTable, B-trees keep key-value pairs sorted by key, which allows efficient key-value lookups and range queries. But that’s where the similarity ends: B-trees have a very different design philosophy.
The log-structured indexes we saw earlier break the database down into variable-size segments, typically several megabytes or more in size, and always write a segment sequentially. By contrast, B-trees break the database down into fixed-size blocks or pages, traditionally 4 KB in size (sometimes bigger), and read or write one page at a time.
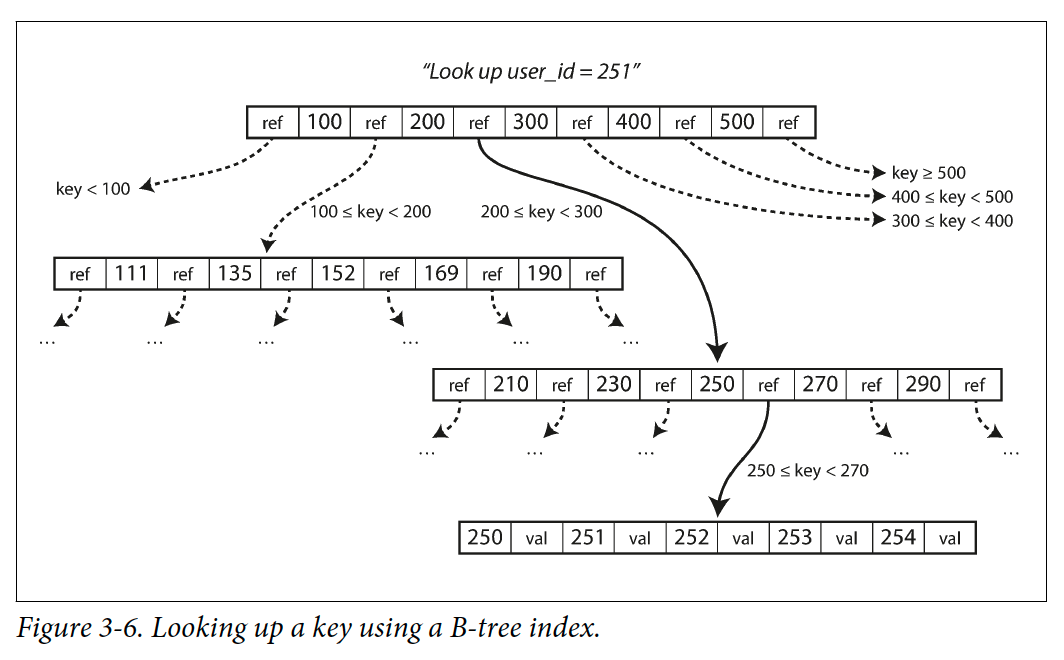
One page is designated as the root of the B-tree; whenever you want to look up a key in the index, you start here. The page contains several keys and references to child pages. Each child is responsible for a continuous range of keys, and the keys between the references indicate where the boundaries between those ranges lie.
Making B-trees reliable
The basic underlying write operation of a B-tree is to overwrite a page on disk with new data. Moreover, some operations require several different pages to be overwritten. This is a dangerous operation, because if the database crashed after only some of the pages have been written, you end up with a corrupted index.
In order to make the database resilient to crashes, it is common for B-tree implementations to include an additional data structure on disk: a write-ahead log (WAL, also known as a redo log). This is an append-only file to which every B-tree modification must be written before it can be applied to the pages of the tree itself.
An additional complication of updating pages in place is that careful concurrency control is required if multiple threads are going to access the B-tree at the same time - otherwise a thread may see the tree in an inconsistent state. This is typically done by protecting the tree’s data structure with latches (lightweight locks).
Comparing B-Trees and LSM-Trees
LSM-trees are typically faster for writes, whereas B-trees are thought to be faster for reads. Reads are typically slower on LSM-trees because they have to check several different data structures and SSTables at different stages of compaction.
Advantages of LSM-trees
A B-tree index must write every piece of data at least twice: once to the write-ahead log, and once to the tree page itself (and perhaps again as pages are split). There is also overhead from having to write an entire page at a time, even if only a few bytes in that page changed. Some storage engines even overwrite the same page twice in order to avoid ending up with a partially updated page in the event of a power failure.
Log-structured indexes also rewrite data multiple times due to repeated compaction and merging of SSTable. This effect is known as write amplification.
Moreover, LSM-trees are typically able to sustain higher write throughput than B-trees, partly because they sometimes have lower write amplification, and partly because they sequentially write compact SSTable files rather than having to overwrite several pages in the tree. This difference is particularly important on magnetic hard drives, where sequential writes are much faster than random writes.
LSM-trees can be compressed better, and thus often produce smaller files on disk than B-trees. Since LSM-trees are not page-oriented and periodically rewrite SSTable to remove fragmentation, they have lower storage overheads.
Downsides of LSM-trees
A downside of log-structured storage is that the compaction process can sometims interfere with the performance of ongoing reads and writes.
An advantage of B-trees is that each key exists in exactly one place in the index, whereas a log-structured storage engine may have multiple copies of the same key in different segments. This aspect makes B-trees attractive in database that want to offer strong transactional semantics: in many relational databases, transaction isolation is implemented using locks on range of keys, and in a B-tree index, those locks can be directly attached to the tree.
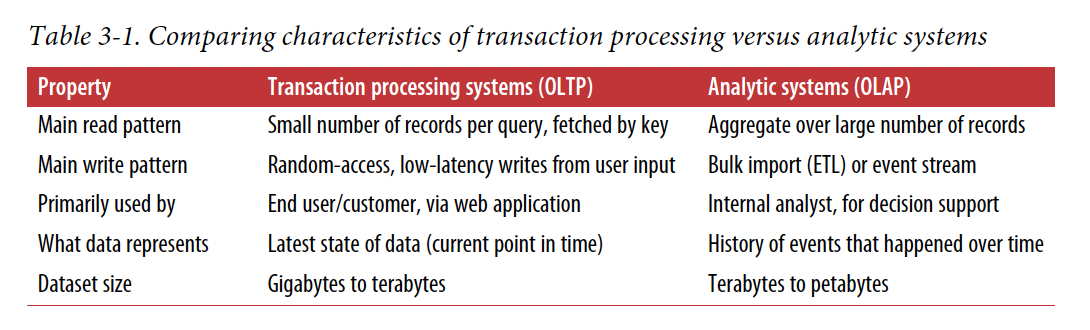
Transaction Processing or Analytics?
OLTP System: online transaction processing, OLTP System: online analytic processing.
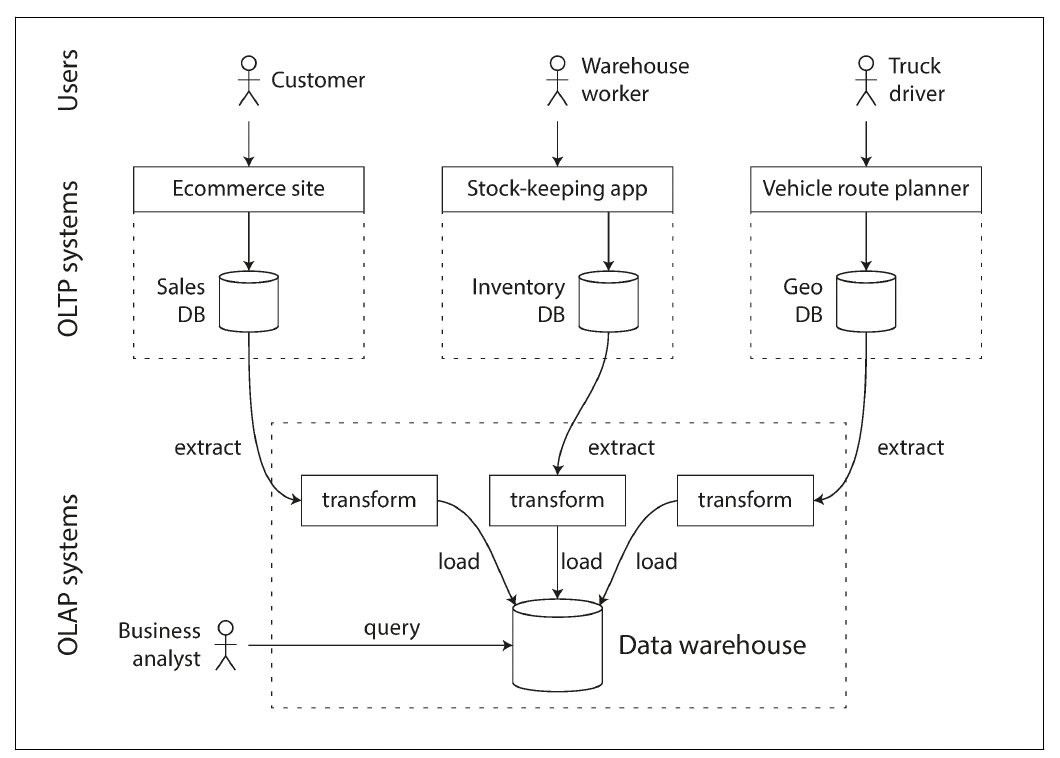
Data Warehousing
A data warehouse, by contrast, is a separate database that analysts can query to their hearts’ content, without affecting OLTP operations. The data warehouse contains a read-only copy of the data in all the various OLTP systems in the company. Data is extracted from OLTP databases (using either a periodic data dump or a continuous stream of updates), transformed into an analysis-friendly schema, cleaned up, and then loaded into the data warehouse. This process of getting data into the warehouse is known as Extract–Transform–Load (ETL).
Stars and Snowflakes: Schemas for Analytics
The name “star schema” comes from the fact that when the table relationships are visualized, the fact table is in the middle, surrounded by its dimension tables; the connections to these tables are like the rays of a star.
A variation of this template is known as the snowflake schema, where dimensions are further broken down into subdimensions.